Note: This update is a little bit on the technical side. If that doesn’t scare you, read on…
A New Model For Predicting Unknown Words
One of the main goals of the first phase of this project is to build a model that can predict the likelihood that a someone at a given level will know a given Korean word. This is important for not just predicting what words need additional explanation, but also to write those explanations in words the reader will understand.
In my last post, I showed you an early, primitive model I built using word frequency. I also said that I was working on a much smarter model. It’s time to present some of my progress.
I will not go into the technical details, but using probability theory and the ~35,000 words marked from the survey responses, I was able to produce the new model illustrated below. As before, the red dots represent unknown words, and blue dots represent known ones.
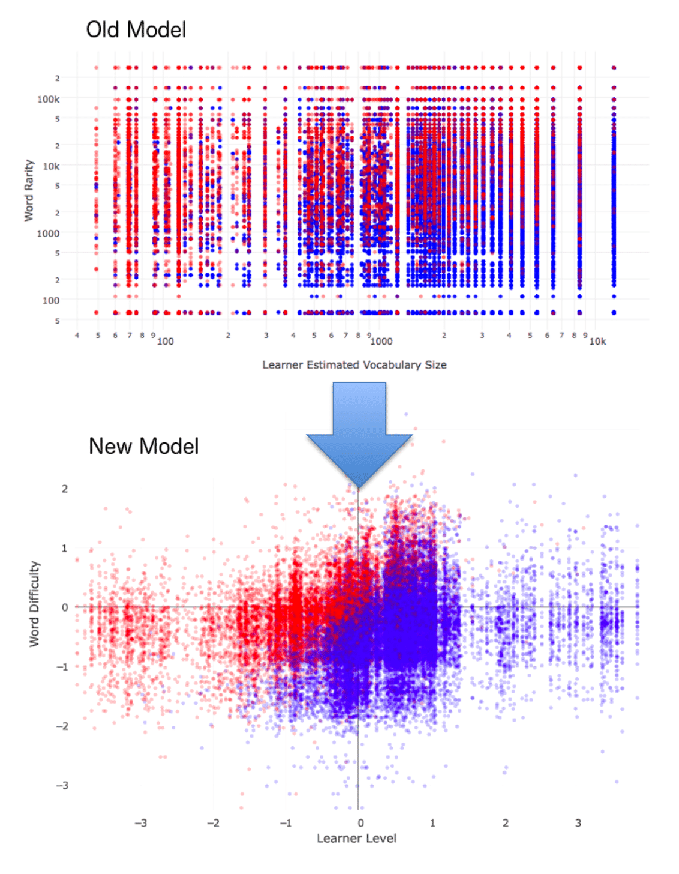
As we can see, the old model was a bit of a confused mess. In the new model, by comparison, the red and blue dots are much better separated, meaning the model is much better at predicting what words readers do and don’t know.
With this new model, we can predict what words readers won't know with much more accuracy. In particular, if this model knows what someone’s Korean level is, then it can predict roughly 80% of the words in an essay that he/she won't know before he/she even sees that essay. If we can generate elaborations for all those words, this could potentially increase his/her understanding of the text from knowing 90% of the words to knowing 98% of the words. Research tells us that this is the difference between being able to understand almost nothing and being able to understand almost all of a text (Hirsh et al. 1992).
The main drawback of this model is that it only works for words that appear at least once among all the essays in the survey, which consists of about 3,500 families of related words. There are thousands of words that aren’t included in the survey yet. So, my next step is to build a more general model that will work for any Korean word. I’ve already made a good progress towards that goal. I’ll post an update on that in another week or so.
Also, new features are being added to the website, which I will post about within the next few days.
References
- David Hirsh, Paul Nation, et al. What vocabulary size is needed to
read unsimplified texts for pleasure? Reading in a foreign language,
8:689–689, 1992.